Disclaimer: This article is based an analysis of yet to be confirmed facts, therefore treat this is a ‘what-if’ type analysis into probable events or technical sets up that could have led to the outage. The full post mortem analysis won’t be out for a few days, we wait with baited breath…
Yesterday, at around 3.30pm AEST, people started to notice that Windows PC were restarting and going into the Blue Screen of Death (BSOD) – a fatal non operating state for a Windows machine. Once in such a state it requires manual intervention to restart (more on this later). Before long, millions, if not hundreds of millions of machines were being impacted globally. Update: turns out just over 8 million machines were directly impacted, no figures yet on what was indirectly impacted, which will be higher.
TL/DR – Root Cause
It turns out the root cause, as best as we can tell at this stage, is that a virus/malware definition file was pushed out by CrowdStrike to its Falcon Sensors (software installed on their customers computers to detect and block viruses and malware) that was malformed enough to cause the receiving machines to go into a BSOD state when they tried to process the file. Rebooting the machines did not help as the update would be applied again and it would go into the BSOD state again.
TL/DR – The fix
As described on the CrowdStrike site, either reboot the host to see if it will receive the updated definition file (they call it a channel file) or you need to boot the machine into Safe Mode, locate the %WINDIR%\System32\drivers\CrowdStrike directory and remove the file matching “C-00000291*.sys” and delete it, then reboot. You may need the BitLocker recovery key if the host is encrypted. Good luck!
Suspected Root Cause
Based on reports on the Internet, it looks like the malformed channel file was able to cause a null pointer dereference fault or a similar level exception event, which, given the Falcon Sensor is running in a privileged kernel environment, triggers an instant kernel panic and a BSOD to halt the system. One such stack track is shown below.
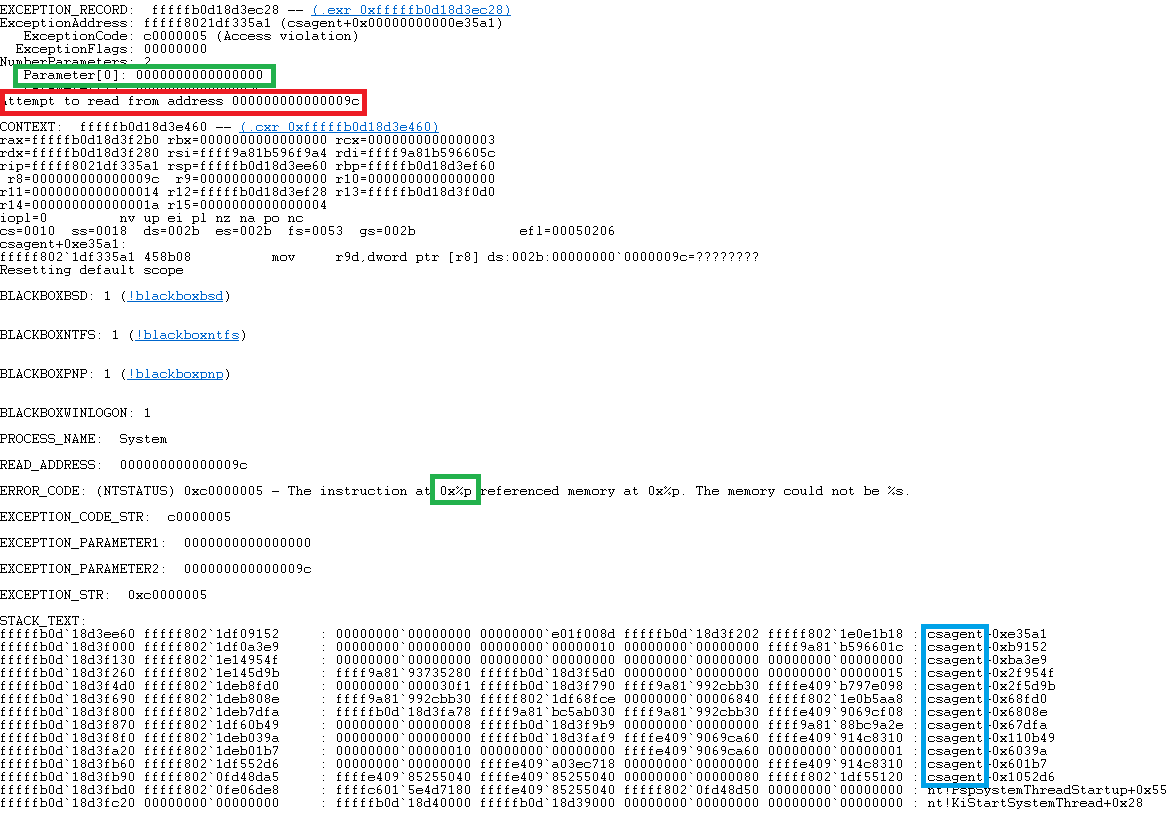
The Error text is highlighted in Red, showing an attempt to read from an address at 00000009c, but the real killer is what highlighted in Green, this shows it was using the contents of memory address 0000000000000 to then use as a pointer to read memory from another location – not good. We know this is CrowdStrike code from the Blue box, the name of the program is csagent.
So how did this come about? Well there have been a few reports of the bad C-00000291*.sys file containing all zeros rather than data. Now given these files contain some representation of multiple signatures of new malware or viruses for the CrowdStrike engine to detect, its very likely each signature will be of a different length. So how do you read in each definition from a single file? Note: the sys extension has no significance on the format of what the file contains, it varies in usage across the system from text files, to flat databases, to system drivers.
Update: there have also been reports of non-zero containing Channel files causing the same crash, it may well be the same zero byte at a certain place in the file is a root cause, or some other vector is at play.
Inline variable length record handling
The usual way to deal with multiple variable length records in a file is to have a block that gives the length of the following data block, so you can pick out each data block and advance to the next block where you pick up its length and the cycle continues until you get the end of the file. You end up with a file structure like that shown below.
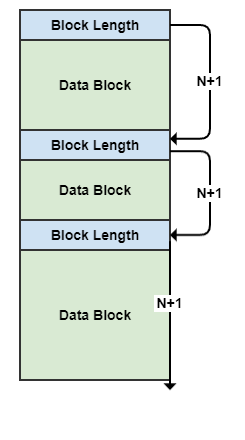
The Blue blocks are contain the length of the following block (which I call N), so you can read the exact length of the Data block in then jump to the end and pick up the next block. I would suspect that the Falcon Sensor code made use of the value of N to reserve memory then attempt to write the following data Block into that memory, as you would want all the signatures you are attempting to match in memory. Other things could well be going on, for example linking signatures to a table of file extensions to match against, but at the start you need to read in the data block into memory and then process it in whatever way needs to be done.
So what happens if you feed in a file full of zeroes into such a processing system? Well, the first block length will be read as zero length, the program will then try to reserve memory of zero length, which is an error and the underlying routine will likely just return a zero to indicate failure. The program will then try to deference this zero pointer at some point and cause an exception leading to a halt state given the Falcon sensor is operating in a privileged environment. This might not be exactly the precise causal chain, but throwing zeros into a system expecting non-zero values will cause a fence post critical error somewhere along the processing chain (if not checked for).
So how did such a file get created?
I suspect the program on the server side either encountered a storage fault, i.e. either the creation of the individual signatures was faulty or the storage of them was faulty OR the subsequent reading and construction of the channel file was faulty. Given the reports of a file containing all zeros and that it is a single file that is the root cause (from what has been discovered so far) I think its the program creating the channel files at fault. It may be the delivery mechanism that has faulted, but if that was the case I would have expected those impacted to be ‘patchy’ (excuse the pun) in that only a subset of people would be impacted and this wouldn’t require a totally new file to be created to address the problem you just send out the old one correctly to those impacted.
What could have been done differently?
First off the Falcon sensor should not be assuming the Channel file is correctly formed, it should have been scanned first for basic integrity and correctness prior to doing any processing using it. Just checking a checksum is not enough, you need to assume the worst, especially when operating at the kernel level.
In a similar way the delivery stage should perform some basic checks on the file integrity before making a Channel file available for download. Now it may be the file is encrypted and signed prior to the delivery stage, if that is so, whatever was feeding the delivery stage needs to do these checks before it sends the file to the delivery stage and then confirm what the delivery stage has is what it sent to it then flag it valid for onwards delivery. In effect a passing of a baton of correctness is implemented by always verifying what was sent is what was received.
So the ‘trigger’ for this was the bad file, but the ‘fatal error’ in not handling the error case in the machine was also needed for this problem to come about, if either was not present the problem would not have arose. This may point to a lack of systematic end to end awareness of what the generating program and the reading program is responsible for or expecting from the other.
Conclusion
Mistakes happen, its a fact of life living in a technical world. Trouble is the wide usage of common systems creates a set of common mode failure points that if not addressed can generate wide ranging outages such as this. The solution is to have more robust coding and to perform staged rollouts that have an ability to detect the health (or not) of the end systems – if its clear there is a wave of ‘dead’ end system states, assume you are problem and stop pushing updates. It’s likely other remote update services from other vendors have similar design weaknesses, this is something which will require urgent investigation.
I also don’t think the fact this occurred on a Friday is a factor, given this should be a completely automated tool chain distributing malware signatures to clients, its just bad luck it occurred on a Friday. IT teams around the world will be working over the weekend to address this and likely this won’t be fully closed out for a few weeks.
Also, there appears to be much discussion online about if this was a security incident or not. According to CrowdStrike, for them, it was NOT a security incident, they did not get hacked, it was just buggy data or code. As for the impacted businesses, the impact could range from zero to a full on security incident, it all depends on what the BSOD boxes were doing for the business, they might have been doing nothing critical to something utterly core to the business and its security. So we cannot generalise to any one impact statement, its individual per business. So, for businesses impacted, they need to do ‘blast radius’ impact discovery exercise and see if the security surface around critical services could have been impacted, then confirm for these services if everything is in a known good state (no CIA events).
Addendum
Apparently CrowdStrike have a history of pushing out broken updates, in April they pushed updates that broke Debian and Rocky Linux installs. The same also occurred after upgrading to RockyLinux 9.4 .
Also it looks like this recent update ignored all the staging policy controls their customers had and went everywhere all at once. This could be due to the policy controls being implemented at the end device and not from the centre when deployed. Which would make sense, as you would not want to be globally tracking for all customers what version each device is at and then working out what updates to push according to their individual policies. Also such a model supports centralised IT deployment management of updates and local policy control. Correction: it appears versioning staging controls are only applied to the Falcon software itself and NOT to Channel Files, which are always instantly applied.