First off, do you know what the biggest single cause of security vulnerabilities and successful attacks against computer systems is? A lot of people think of insufficient access controls, a lack of process, SQL injection, etc but there is something more fundamental sitting behind a lot of these that often gets overlooked. I’m talking about good old human error. A recent report from Standford university found that up to 88% of all data breaches were caused by some form of employee mistake. The report focussed on the typical employee security interactions, such as clicking on a Phishing link, or giving away sensitive information to some unauthorised to receive it; but there is a class of employees who have a more direct influence on the security of most online services: software engineers.
Over the years, I’ve lost count of the number of times a mistake or oversight by a software engineer has created a vulnerability that could or did lead to ultimately a compromise. Computing systems are complex and often labyrinth-like in their construction. Engineers are often under time and resource pressures to get new features out, and qualities like security can sometimes get ‘squeezed’. Even with the best oversight and testing, things get missed, software engineers are not perfect and most hackers know this.
So what are the root causes of technical human error being such a risk?
#1 Limited comprehension horizon
Each engineer can only spend a certain amount of time understanding the environment and systems they are tasked with supporting and developing upon. Such a systematic awareness quickly fades the further you get away from their root concerns.
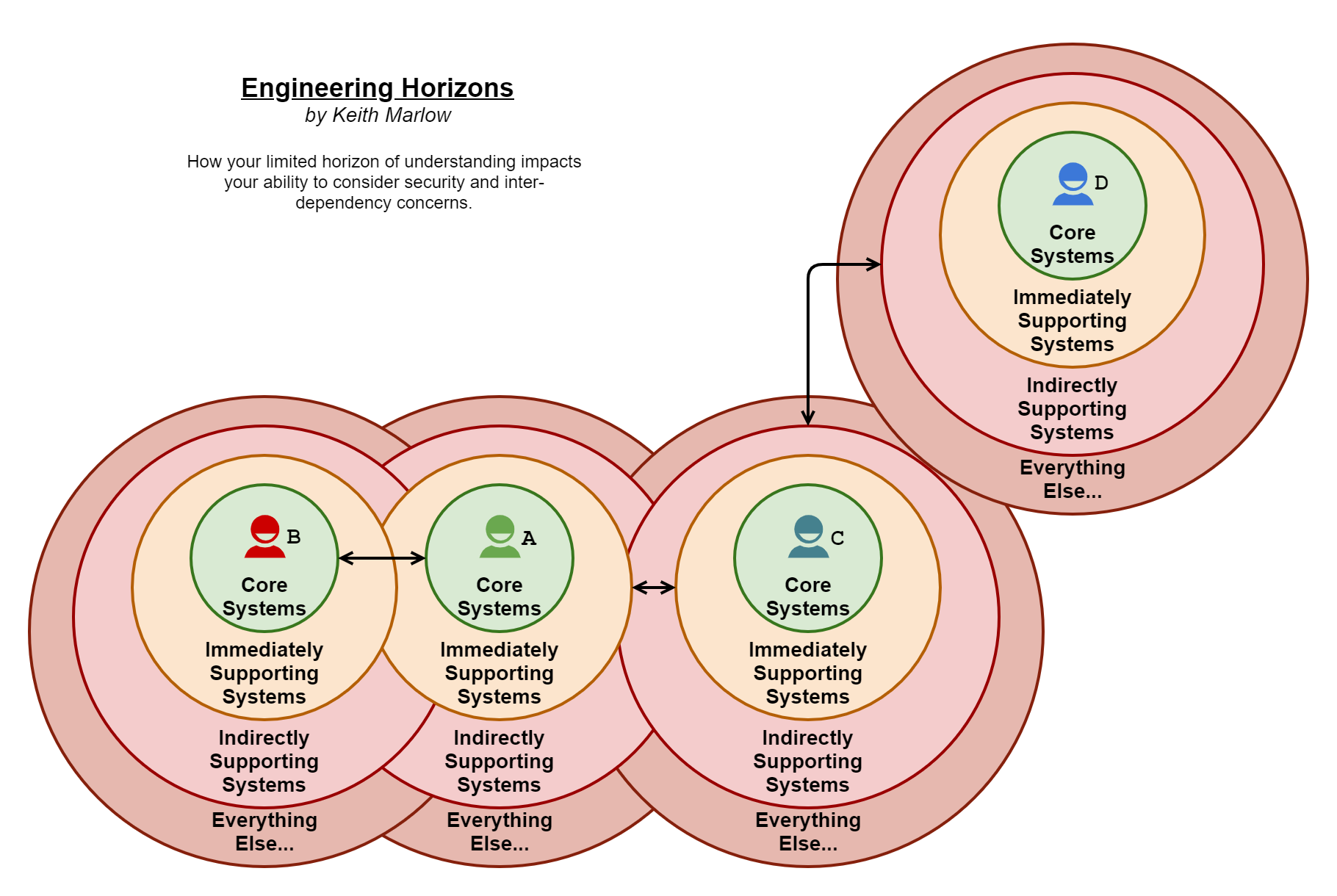
By way of example, in the above diagram, we have four colourful engineers (A, B, C and D) all associated with the Core Systems they are directly responsible for. These Core Systems are coloured green as the respective engineers have good knowledge of their systems, confidence is high that with such systems they won’t cause security-related human errors that much (in other words awareness and process coverage will be good). Next out is the ring of Immediately Supporting Systems, the engineers know of these and how to use them but are not directly responsible for them, they are a close dependency. Again I would expect the engineers to know the strengths and weaknesses of such systems and code the interfaces to them in quite a secure manner, hence the yellow background, but this is not as good as the core.
Next out are the Indirectly Supporting Systems, these are the systems behind other systems, they are invisible to the Core System engineers but they do depend on them without them knowing it. A bit like a house depends on the ground it’s built on, you have no clue if immediately below your house is solid ground or a deep void waiting to swallow the house whole. This is not feasible for most to discover, they just look at the other houses in the vicinity and assume it must be safe as nothing has fallen down a hole, yet… Such a lack of awareness combined with an assumption of safety by default creates an environment for those assumptions to be dangerously wrong, hence the light Red background.
Then of course there is everything else out there, which include systems and services the Indirectly Supporting Systems could be utilising. This is why 3rd party integrations can be so dangerous, you quickly lose sight of where the dependencies end (if ever).
Going back to the diagram, I’ve put in some arrowed lines showing some calling or operational dependencies between systems at different layers, can you tell which lines the Core System engineers would be directly aware of? Yep, only the line between A and B, all the rest are hidden, they may be aware of the data exchange but are not directly knowledgeable on how that is achieved… It is outside of their remit or systematic radar to know. Now you could consider the linkage between A and C as something they might have a higher awareness of, but the question is, what scope of control do they have over that? Can they enact a change for the better with regards to security? Are they able to call out a problem (if they have time to find one) and see it gets fixed? Remember their scope of control also fades away the further from the core to a point where they have no control at all for the invisible 3rd parties.
#2 Dangerous Defaults
All computer systems have default configurations or controls around their operation. The trouble is it is so easy for one mistake in the wrong place to suddenly turn off a whole raft of security controls and your systems get exposed. The trouble is that the defaults are usually set as ‘all security is off’ as if security is something you need to be layering on after the fact.
This mindset I’ve seen in everything from firewalls through to content management systems and web frameworks. Yes, it makes it easier to get started but this default security off mindset is a landmine in your systems just waiting to go off. Software engineers need to avoid repeating this mistake.
#3 Failing Open
Associated with dangerous defaults is another equally as dangerous state for a system to get into – the fail-open state. You would be surprised by the number of WAF or routing devices that if given an invalid configuration would default to letting everything through and do so silently.
Software engineers need to consider a failure in the configured state to be just that, a critical failure.
Now the above three enablers for human error by Software engineers are in no way exhaustive, but they are the main ones that can drive other problems, like wrong assumptions.
So what can one do? Especially given that the causes of such human error could be in systems beyond your control?
Solutions, divide and conquer
I use 5 main techniques in software development and systems design to both reduce the likelihood of human error and also to reduce the impact of such technical errors.
#1 Defence in Depth
The idea here is to have multiple overlapping security controls around your systems and services, so if one is compromised (or fails due to human error) you are still left protected.
If you only take away one thing from reading this article, be it this, defence in depth will often save you when others will fail. People will make mistakes, and software engineers particularly so, and if you can properly implement defence in depth, such mistakes will not lead to a compromise.
To learn more about Defence in Depth read this article.
#2 The Default is Secure
When coding a system or service, the default state is to be secure. The system or service should not even start if the security configuration is invalid. This may sound tough but again an error in configuration should not lead to a possible compromise.
Now you may have it that you need to use the system in a development environment where having all the security controls turned on would be painful, so have an ‘env=dev’ or equivalent control in the configuration of that environment to turn them off BUT when going to production you need to have a gate to ensure such a control is nowhere to be seen in the release candidate – it cannot get to or operate in the Production environment without the security controls.
#3 Validate and Verify Everything
When you take input from any other system, even if it is a system you control, you need to validate that input is what it claims to be. Never assume what you put into a system is going to be what you get out of it. If you need an integer confirm it is an integer and error if it is not. The number of times I’ve seen engineers just take data from another system and just use it without the slightest amount of validation is almost countless.
If most Software Engineers would validate their data, a lot of compromise vectors would be off the table.
Also aim to do the validation in a way that is difficult to break. For instance, if you have a request routing layer that can do the parameter validation for you, use it! Far better than burying the validation away in some controller that may get broken.
#4 Manage Complexity
Too often technical debt focuses on features or improvements that are quite concrete in nature, for instance, a library upgrade. Technical debt often misses out on treating undue complexity as a serious debt. We all know code that is a true rats nests of IF THEN ELSE’s and duplicate bits and pieces. This often gets put under the rug called ‘refactoring’ and promptly forgotten about. The trouble is that rats nest is a breeding ground for security problems, as hard to follow and comprehend code is by definition going to be hard to prove to be secure.
So instead of saying you are refactoring, call it ‘security rationalisation’ and focus on the areas of the code which are proving most difficult to control in a security sense. This will often have the nice side benefit of leading to more maintainable code.
#5 Training
Before any software engineer does any code that makes it into Production and especially onto the Internet, they need to be at least aware of the following:
- The OWASP top 10 and how to stop them.
- The MITRE ATT&CK knowledge base of adversary tactics and techniques based on real-world observations. This explains how real world attacks proceed through systems and how you can break an attack.
- Defensive coding techniques to ensure errors and failures do not proceed to insecure states.
The goal here is to ‘open their minds’ to the universe of security risks out there and how they have a very important part to play in keeping systems, and the data they hold, secure. Encourage them to investigate security areas of interest to them, be that cryptography, random number generators, zero-knowledge proofs, social engineering, etc.
Conclusion
Human error is everywhere, and especially in software development, but with the above techniques, such errors can have their likelihood and impact of leading to a security vulnerability greatly reduced.