Given the recent outage with AWS and how some bad typing could bring down a large part of the cloud infrastructure of Amazon I thought it might be informative to pull the veil back a bit on how cloud systems work and what are the common failure modes and how to guard against it.
A brief History lesson
To understand the current set up of cloud infrastructure its important we understand how we got here first…
A tail of many Colos…
Back in the ancient history of the Internet, the 1990’s, it was quite common for businesses to provide their online services from one Colocation (Colo) facility. A Colo facility is basically a specially designed building which exists to house racks of computers in an environmentally controlled, secure and power guaranteed space with good access to networking infrastructure. It saves a business having to do the same thing at their own offices, which would be a rather expensive undertaking as you would need to reproduce all the environmental controls, security and power backups making use of expensive office space.
Depending on the size of business concerned, they may just have a few machines in the Colo, up-to a couple of hundred or more. The Colo then was essentially a physically shared space – one company might have machine racks #1 and #2, where as another might have machine racks #3 to #10. (A machine rack is a metal box about 6 feet tall into which you can slot your computers).
Now this is all fine and dandy, but there are a few difficulties with this:
- Adding or changing hardware is inherently expensive – you have to get someone (or have someone employed) to do all the hardware work;
- Adding or changing hardware takes a lot of time – no ‘instant on’, we talking about a few hours on a good day (they have a box to hand) to get a new machine up and running – then there is the paperwork..
- You are often stuck with what you are given for a long time (years) – this is simply because there is a direct investment into a given machine, moving to something else was often just too darn painful, no one budgets for upgrade time.
Now the bigger businesses, with whole floors worth of equipment, often faced risks which smaller businesses could not directly afford to deal with. For instance if the Colo lost its networking (a JCB on the building site next door ate my fibre) then its whole online presence would go dark, this could be a revenue impact well into 6 figures and beyond depending on the size of the operation (not to mention the brand hit). So what they would do is Colocate the Colo – in other words ‘mirror’ everything they had on one site at another site with a layer of ‘smart’ traffic routing on top to send the traffic to the closest Colo which was up at that time. See the diagram below:
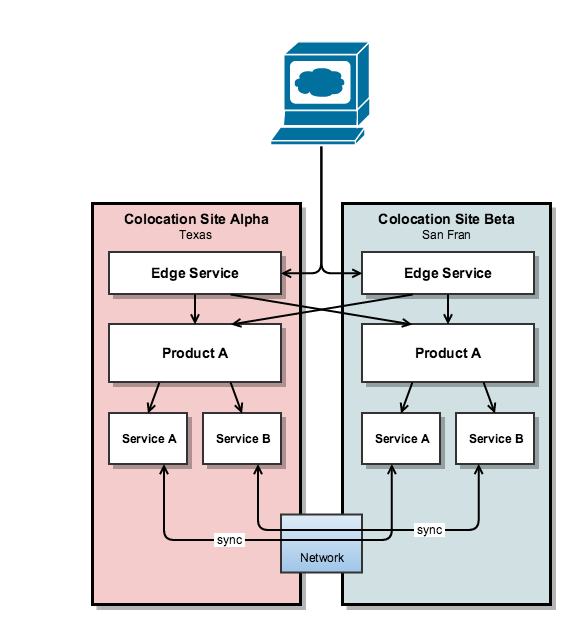
Each Colo (or some other provider) would implement an ‘Edge Service’ which looked after routing traffic to nearest available Colo that had the Product you were after, so in the above diagram we have ‘Product A’ that exists both in Colo Site Alpha and Beta, which are physically in Texas and San Fran. Idea being here anything nasty happens to Texas, San Fran can pick up the slack, etc.
Quite often such products would make use of common services, say User data storage, general databases or stats collection, which then provided as part of their offering a synchronisation (everyone has a copy of the data) or a data distribution feature (don’t care where the data actually is just provide it when I ask) – so the Products did not have to look after doing this. Although some Products would even implement their own synchronisation for time critical data (say online bids).
This on the whole worked quite well of the big end of town, as they had the money and resources to get a sensible return from such actions in reducing their risks to business. The trouble was even for such businesses the costs where prohibitive and so there was a drive to be smarter and cheaper in getting resilience.
Rise of the virtual machine/service
Around 2001 VMware released software that made it possible on PC type machines (which a lot of Colos contained) to run Virtualised Operating System environments. In essence this created a ‘disconnect’ between the underlying physical hardware and what software could be run on it a given time. In effect Operating Systems and all their applications, data and set up became things that could be moved between machines in their own right. This also made it possible to run multiple virtual machines on the one physical machine and stop and start them at will. This was a big plus for businesses, as one of the challenges faced is getting sufficient utilisation out of the machines in the racks as you need enough capacity to deal with the peaks; before virtualisation you just had to leave machines idle, now you could shuffle around services or ‘pack’ them in much more densely and thereby improve your utilisation.
Autoscaling we shall go..
Then someone had the bright idea of instead us humans having to work out how much of something should be ‘up’ at any given time, why not let the computers themselves decide where appropriate? With virtual images it was as easy to spin up 5 copies as it was 50, then scale back. You could even automatically power down the physical machines when not needed.
Auto provisioning we shall go…
Then someone had another bright idea, why not package up the whole application, with the details of everything it needs into a ‘deployment recipe’ – so we could auto magically set up multiple copies of a product by configuration and the computers take care of working out where everything goes and how to wire it all up.
Today’s Cloud Infrastructure
So given the above concepts of:
- Virtualised Machines
- Auto scaling
- Auto provisioning
You have the core elements of the modern day cloud infrastructure where the products and services very rarely run ‘directly’ on the hardware in the Colo – instead they all operate in virtualised environments; essentially meaning its no longer directly important what something runs on just as long as it can run. This is an important concept to remember, as when a cloud operator presents a new Service, its as likely to be as virtualised as the Products using the Service – in effect cloud operators make good use of their own frameworks to implement their services. Which is okay most of time..
Who runs what and where?
One of the big problems faced with cloud systems now is literally keeping track of what is running where and who is using it. Management of this data and keeping ahead of demand is a big problem. This is why operators like Amazon have invested so much in specialised hardware and infrastructure, anything they can do to simplify the act of provisioning and configuration, whilst keeping ‘cross talking’ to minimum is of prime importance. Cross talk is when logically separate systems compete unintentionally over a shared resource; this could be network bandwidth that hits a ceiling or it could be CPU availability, etc – the problem is this contention was not planned for. In Cross talk is a hidden interdependency that was not tracked anywhere.
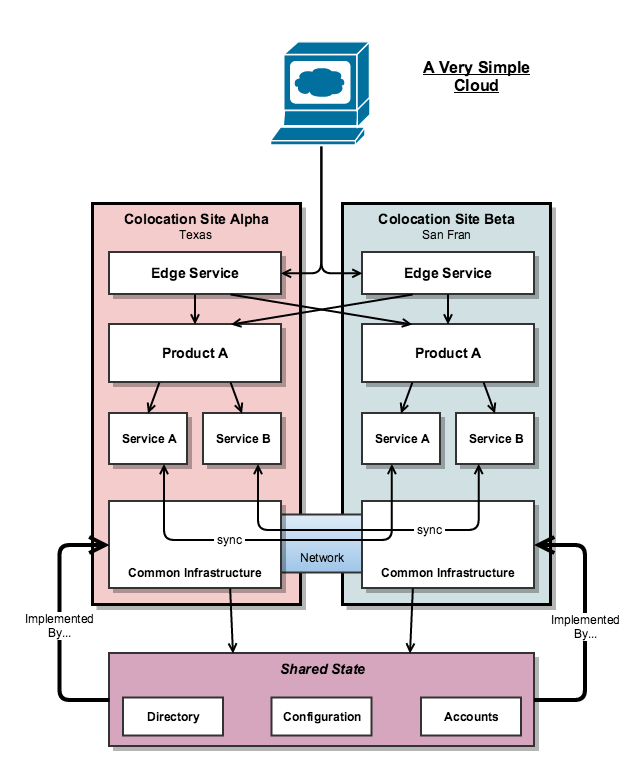
The above diagram of a basic modern cloud environment shows this reuse very nicely – the ‘Shared State’ component at the bottom has to be implemented on something and it this case its the Common Infrastructure present in each Colo: the virtualisation, messaging and storage systems which everyone makes use of.
How can Clouds Fail?
In the rare cases that cloud systems fail, they usually fail in one of four ways:
- Networking between Colos – The cloud operators have no direct control over the fibre between their Colos, they are at the mercy of JCB’s, anchors, sharks, fishermen and natural disasters – often Sod’s Law likes to load the dice of fate and the fibre that fails will be the fattest fibre in the network. This means either a Colo (or two) going dark or everything going slower. In some ways everything going slower is more of a problem (this indicates things could be backing up, or are out of sync). You can also get network connections that start dropping packets, which can lead to backlogs and unforeseen delays.
- The power goes out – Periodically you are meant to test the backup power supplies at the Colos, sometimes in the act of testing the backup will fail. This causes a loss of service at one Colo and possible data inconsistencies that need resolution when the power comes back. This doesn’t happen that much now as Colos have got smart and do progressive backup testing.
- Run away Cross Talk – essentially a chain of overload events occur which bring to halt everything that depends on the service(s) that get overloaded. Rare but certainly possible, often caused by a core programming error.
- Resource starvation – For what ever reason a core service is denied the resources it needs to provide the required Quality of Service, this then goes on to cause outages of the dependent Products and Services.
What is interesting to note, that in only one of cases above is a cloud outage caused by something other than human action (direct or indirect) – Yep, without people we would not have outages (or rather when the cloud goes down you probably have other things to be worrying about).
How can you guard against cloud outages?
 When guarding against cloud outages, you need to ask yourself the following questions first:
When guarding against cloud outages, you need to ask yourself the following questions first:
- Is being down really a bad thing? – You might be operating in the sort of business where people will come back after a while, the service is not that ‘time critical’ to them. On the other hand it could be a matter of life or death…
- How much are you willing to spend? – Could be you want to spend as little as possible or you want to double (or more) your cloud costs.
- Do you need access to the data 24×7? – It could be that data is being collected or held in the cloud which is critical to your business activities.
If being down is a really a bad thing for you (and you have the budget) the easiest way to stay up is to ‘mirror’ your product to what is called another ‘availability zone’ – in essence another physical distinct Colo in which you run a copy of your services. Often the cloud operator will provide synchronisation services for you, as its in their interest to have you buy more of their services.
If you need to access the data 24×7 then you need to consider what is called ‘second sourcing’ – basically setting up an archive service with another cloud provider (who should be running on their own distinct infrastructure – worth checking). You also need to make sure this is secure and that you can truly access it independently of the main cloud provider.
Another golden rule is not to put all your eggs in the one basket if you can avoid it – so if you cannot afford to mirror your Products at least distribute them across a few Colos. the difference in cost to all having them in the one Colo typically isn’t that great.
If you would like some assistance making your cloud set up more resilient – please get in touch .